I should also mention Oxygen, an SWT desktop XML IDE also based on SWT. It's capable and snappy, and has a great XSLT debugger; but not as feature loaded as XML Spy.
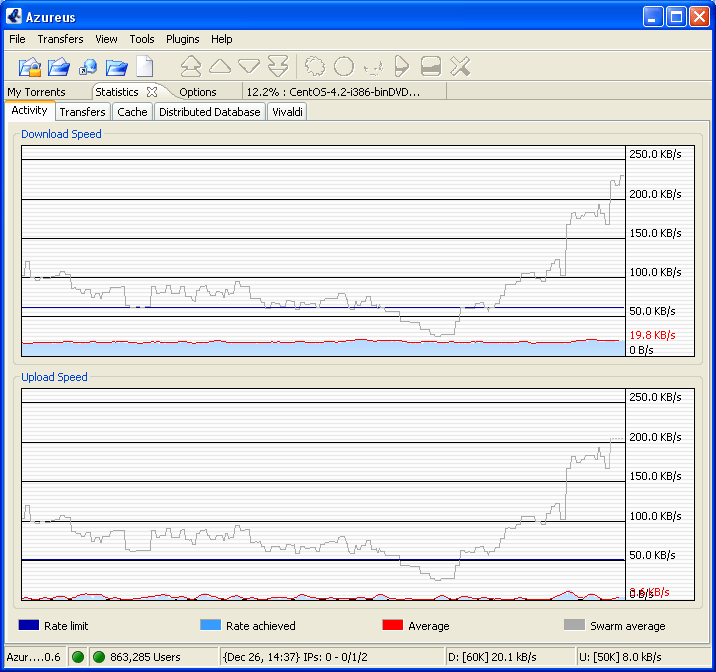
A nice scrolling real time graph from Azureus
I am celebrating today my third anniversary as a reporter of this bug. I reported it Dec 23, 2002 (http://bugzilla.mozilla.org/show_bug.cgi?id=186581 ) and was soon notified that it was a duplicate of this one.
In just a few days the bug will pass its fifth anniversary since originally reported by Stephen Clouse on Dec. 28, 2000, near the end of the last century.
I've subscribed to the "progress" of the bug over the years since then. Here are my picks for each year's highlights:
o 2001: A comment by Hixie (https://bugzilla.mozilla.org/show_bug.cgi?id=63895#c4 ). I didn't understand this one really ( I don't understand any of the technical comments really) but it seems really cool that Hixie has been on the case.
o 2002: Derek (https://bugzilla.mozilla.org/show_bug.cgi?id=63895#c16 ): "This seems like a pretty significant bug, considering that CSS2 positioning is supposed to end dependence on table-based layouts."
o 2003: Boris (https://bugzilla.mozilla.org/show_bug.cgi?id=63895#c25 ) complaining about "pushy bug reporters who demand things as their right without thinking about the fact that ..." yada yada.
o 2004: Joe (https://bugzilla.mozilla.org/show_bug.cgi?id=63895#c37) "Wow... 12-28-2000... Don't hold my breath eh?", followed by Martin's riposte (https://bugzilla.mozilla.org/show_bug.cgi?id=63895#c38) "Please keep those remarks to yourself, this doesn't help."
o 2005: ATom (https://bugzilla.mozilla.org/show_bug.cgi?id=63895#c43): "How are advantages of this behavior? According my opinion is it only disadvantage. How much authors use this behavior? How many pages can change of this behavior cause regression?"
I'm looking forward to lots more analysis and opinion on this bug in 2006!
That's when my crisis struck. I was sitting at the world's foremost metadata conference in a room full of people who cared deeply about the quality of metadata and we were discussing scraping data from descriptions! Scraping metadata from Dublin Core! I had to go check the dictionary entry for oxymoron just in case that sentence was there! If professional cataloguers are having these kinds of problems with RDF then we are fucked....A simpler RDF could take a lot of this pain away and hit a sweet spot of simplicity versus expressivityIn the free vs safe debate, looks like he's making a run at freedom.
The response of subsequent POSTs should be the same as if there had been only one POST so that the client can get the correct response even if there is a network outage in the middle of the first response.
If the server had received and accepted the first request, it will respond with
S: 405 Method Not Allowed HTTP/1.1
Allow: GET
...
If the response status is "405 Method Not Allowed" the client can infer that the earlier POST succeeded. A 2xx response indicates that earlier POST did not succeed, but that this one has. When the client receives either of these responses, it knows that the request has been accepted, and it can stop retrying.
{kind=link}