Bill de hÓra: JORAM in particular is a quality JMS implementation.
Yup. Wellstorm uses JORAM internally and it has proven solid. (The ObjectWeb logger did hijack our logging, an issue we still need to work out). I really haven't caught any JORAM errors, so it meets the ultimate test of infrastructure: It's just there.
If you can't say anything else for Java, you can say it has a great choice among infrastructure packages. Last weekend I added a scripting capability using Rhino. Got the idea at lunch Friday. Took an hour to get something working, the rest of the time framing a decent web UI. Demoed it today.
Monday, January 23, 2006
Encoding the XML infoset in HTML forms
Every month or two I find myself remarking on the awkwardness of constructing XML on the client side. Are HTML clients forever condemned to using XMLHttpRequest? Must we await widespread support for Xforms?
In the spirit of The Simplest Thing That Could Possibly Work: Why don't we just standardize encoding the XML infoset in HTML forms?
Here's how you could POST an Atom entry (compare to example in draft 07):
That form encodes as
The pattern is: Name your HTML form elements using XPath syntax.
(What if all Atom powered blogs supported POSTing of form data in addition to the Atom syndication format? I guess I could construct a website that exposes a form like this, and permits you to direct your entry to any blog service. Not sure how useful that would be, but it doesn't seem any less useful than enabling a rich client do it ;) ).
I'm just reiterating the point I made here some time ago: form data is a perfectly good hypermedia representation, and it has a ton of support already in place.
In the spirit of The Simplest Thing That Could Possibly Work: Why don't we just standardize encoding the XML infoset in HTML forms?
Here's how you could POST an Atom entry (compare to example in draft 07):
<form action="http://localhost/foo" method="POST">
<input type="hidden" name="/entry/@xmlns" value="http://www.w3.org/2005/Atom"/>
Title: <input type="text" name="/entry/title">
Link: <input type="text" name="/entry/link/@href"/>
Id: <input type="text" name="/entry/id"/>
Updated: <input type="text" name="/entry/updated">
Summary: <input type="text" name="/entry/summary">
<input type="submit" name="submit" value="Submit">
</form>
That form encodes as
%2Fentry%2F%40xmlns=http%3A%2F%2Fwww.w3.org%2F2005%2FAtom&%2Fentry%2Ftitle=Atom-Powered+Robots+Run+Amok&%2Fentry%2Flink%2F%40href=http%3A%2F%2Fexample.org%2F2003%2F12%2F13%2Fatom03&%2Fentry%2Fid=urn%3Auuid%3A1225c695-cfb8-4ebb-aaaa-80da344efa6a&%2Fentry%2Fupdated=2003-12-13T18%3A30%3A02Z&%2Fentry%2Fsummary=Some+text.&submit=Submit
The pattern is: Name your HTML form elements using XPath syntax.
(What if all Atom powered blogs supported POSTing of form data in addition to the Atom syndication format? I guess I could construct a website that exposes a form like this, and permits you to direct your entry to any blog service. Not sure how useful that would be, but it doesn't seem any less useful than enabling a rich client do it ;) ).
I'm just reiterating the point I made here some time ago: form data is a perfectly good hypermedia representation, and it has a ton of support already in place.
Monday, December 26, 2005
Java SWT rich clients: Azureus, Oxygen
Azureus Bittorrent client is a pretty impressive example of a Java rich client based on SWT. It's responsive and rich graphically. Did they finally get the equivalent of Java2D in SWT? Azureus has lots of scrolling realtime graphs to diagnose why your 2GB download goes so slowly. .NET isn't your only choice for a rich client.
I should also mention Oxygen, an SWT desktop XML IDE also based on SWT. It's capable and snappy, and has a great XSLT debugger; but not as feature loaded as XML Spy.
I should also mention Oxygen, an SWT desktop XML IDE also based on SWT. It's capable and snappy, and has a great XSLT debugger; but not as feature loaded as XML Spy.
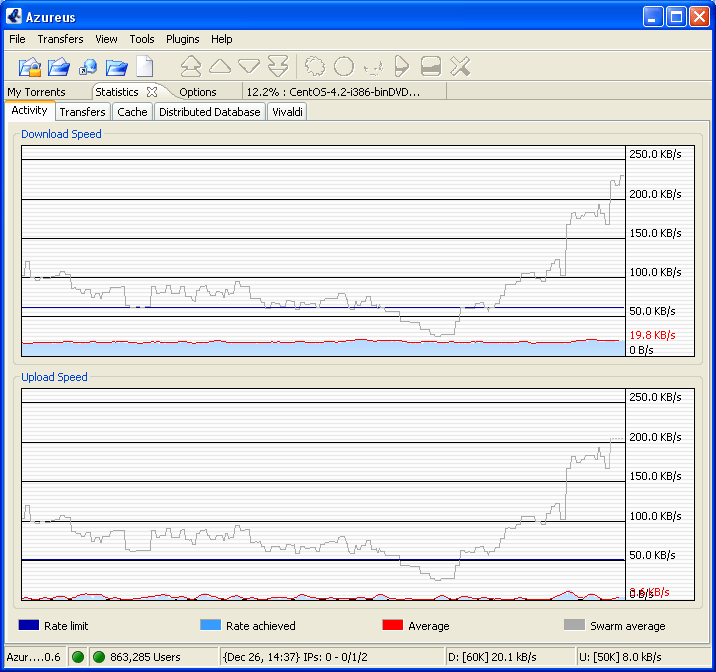
A nice scrolling real time graph from Azureus
{kind=link}
Friday, December 23, 2005
Oldest Mozilla Bug (Not)
Every software organization has its oldest bug. The older the bugs are, the less likely you are to fix them. If I remember correctly, at my last company , after three years the oldest bug we never had fixed was number 11. Usually a bug becomes irrelevant after a number of years.
Three years ago today I reported a Mozilla CSS rendering bug. The details won't interest you, unless you're really into using CSS to replace tables. The workaround to the bug is: Use a table. Surely it's not the oldest bug in Mozilla, but it may be up there. And web developers are still actively encountering it.
Most interesting is the dynamic of getting a bug fixed in Mozilla. I reported the bug three years ago today, but it was a duplicate: A guy originally reported it on December 28, 2000. Today I thought it worthwhile to commemorate my third anniversary, and the approaching fifth anniversary, of Bug 63895:
Three years ago today I reported a Mozilla CSS rendering bug. The details won't interest you, unless you're really into using CSS to replace tables. The workaround to the bug is: Use a table. Surely it's not the oldest bug in Mozilla, but it may be up there. And web developers are still actively encountering it.
Most interesting is the dynamic of getting a bug fixed in Mozilla. I reported the bug three years ago today, but it was a duplicate: A guy originally reported it on December 28, 2000. Today I thought it worthwhile to commemorate my third anniversary, and the approaching fifth anniversary, of Bug 63895:
I am celebrating today my third anniversary as a reporter of this bug. I reported it Dec 23, 2002 (http://bugzilla.mozilla.org/show_bug.cgi?id=186581 ) and was soon notified that it was a duplicate of this one.
In just a few days the bug will pass its fifth anniversary since originally reported by Stephen Clouse on Dec. 28, 2000, near the end of the last century.
I've subscribed to the "progress" of the bug over the years since then. Here are my picks for each year's highlights:
o 2001: A comment by Hixie (https://bugzilla.mozilla.org/show_bug.cgi?id=63895#c4 ). I didn't understand this one really ( I don't understand any of the technical comments really) but it seems really cool that Hixie has been on the case.
o 2002: Derek (https://bugzilla.mozilla.org/show_bug.cgi?id=63895#c16 ): "This seems like a pretty significant bug, considering that CSS2 positioning is supposed to end dependence on table-based layouts."
o 2003: Boris (https://bugzilla.mozilla.org/show_bug.cgi?id=63895#c25 ) complaining about "pushy bug reporters who demand things as their right without thinking about the fact that ..." yada yada.
o 2004: Joe (https://bugzilla.mozilla.org/show_bug.cgi?id=63895#c37) "Wow... 12-28-2000... Don't hold my breath eh?", followed by Martin's riposte (https://bugzilla.mozilla.org/show_bug.cgi?id=63895#c38) "Please keep those remarks to yourself, this doesn't help."
o 2005: ATom (https://bugzilla.mozilla.org/show_bug.cgi?id=63895#c43): "How are advantages of this behavior? According my opinion is it only disadvantage. How much authors use this behavior? How many pages can change of this behavior cause regression?"
I'm looking forward to lots more analysis and opinion on this bug in 2006!
Friday, November 25, 2005
Common sense
RESTful design is not an end in itself: If you find yourself adding complexity to honor the constraints of REST, consider the benefit of the complexity and only do it if the benefit is clear. Here's a case of a guy asking this perfectly ordinary question: How can I use POST to execute a query where the query string is too long to stuff into an URL? This question pops up once a year on the rest-discuss list.
Some responded with helpful suggestions to have the POST create a temporary resource, which when you GET it, returns the query results. Mark doesn't think this is restful. But I do, because the client and server understand that the semantics of whatever document told the client the URL to POST the query to, demand that the POSTed doc be a query document, and that the Location header in the response be the URI where the client can retrieve query results. It's all in the mime type of the document containing that link.
But that's neither here nor there. It's wrong to create this intermediate resource if you simply want to get the query results as if your URL were short enough to do a GET. It doesn't enhance interoperability, and it adds complexity to the server design, which now has to manage the lifecycle of these temporary resources. I'm not saying returning 303 is a bad thing; just that in the case where you really just want to emulate GET and workaround an artificial limitation, just POST the query and return the result in the entity body. This is perfectly RESTful, but that's beside the point: Keeping it simple is always a higher value than perfect RESTful design, as long as you don't degrade interoperability.
Some responded with helpful suggestions to have the POST create a temporary resource, which when you GET it, returns the query results. Mark doesn't think this is restful. But I do, because the client and server understand that the semantics of whatever document told the client the URL to POST the query to, demand that the POSTed doc be a query document, and that the Location header in the response be the URI where the client can retrieve query results. It's all in the mime type of the document containing that link.
But that's neither here nor there. It's wrong to create this intermediate resource if you simply want to get the query results as if your URL were short enough to do a GET. It doesn't enhance interoperability, and it adds complexity to the server design, which now has to manage the lifecycle of these temporary resources. I'm not saying returning 303 is a bad thing; just that in the case where you really just want to emulate GET and workaround an artificial limitation, just POST the query and return the result in the entity body. This is perfectly RESTful, but that's beside the point: Keeping it simple is always a higher value than perfect RESTful design, as long as you don't degrade interoperability.
Thursday, September 29, 2005
Free vs Safe in semweb
Ian Davis is having an RDF breakdown. Seems Dublin Core can't seem to get dc:creator quite right:
That's when my crisis struck. I was sitting at the world's foremost metadata conference in a room full of people who cared deeply about the quality of metadata and we were discussing scraping data from descriptions! Scraping metadata from Dublin Core! I had to go check the dictionary entry for oxymoron just in case that sentence was there! If professional cataloguers are having these kinds of problems with RDF then we are fucked....A simpler RDF could take a lot of this pain away and hit a sweet spot of simplicity versus expressivityIn the free vs safe debate, looks like he's making a run at freedom.
Monday, September 26, 2005
Technorati. Sigh.
If I do a Technorati search for some URL (say, this blog), I get the Technorati search page. In the upper right I notice an image "Add to watch list". That's right, if I click the link, the browser will do an HTTP GET on URL http://technorati.com/watchlist/add/hughw.blogspot.com, and change my watch list. I guess it must be a good thing that the above URL modifies your watchlist, not mine, if you click it. Although a lot of people would call it a bad thing for your identity cookie to make an URL identify one resource for me, another resource for you. I guess if you're going to introduce side effects for GET, you might as well fix it by making the URI identify multiple resources.
Update: I could be off base with the side effects argument. The side effect of clicking the link N times really is the same as clicking it once, which is all RFC 2616 asks. Something in me reacted to having clicking a link change some state, but I guess I shouldn't get my panties in a bunch about it. Still, the URL identifies your watch list for you, and my watch list for me. That's wrong, isn't it?
Update: I could be off base with the side effects argument. The side effect of clicking the link N times really is the same as clicking it once, which is all RFC 2616 asks. Something in me reacted to having clicking a link change some state, but I guess I shouldn't get my panties in a bunch about it. Still, the URL identifies your watch list for you, and my watch list for me. That's wrong, isn't it?
Saturday, September 24, 2005
Search is the new Forms
I'm late to the Atom web services party. Why didn't someone tell me the Atom Publishing Protocol covers all of the territory I've been discussing for RESTful WITSML web services?
Now OpenSearch promises that I can expose a search URL over my Atom service that can be used by search aggregators to do sort of intelligent searching.
If anybody can search my web service using a standard protocol, to discover URLs of resources they are interested in, it's the poor man's equivalent of having a forms language. Aren't 90% of the forms you fill out on the web some form of search?
I can force a lot of the semantics of my web service into search. What can't you model as a search? You can model UDDI as search. You can model any web catalog as a search. Heck, you can model solving a differential equation as a search.
Search may substitute for a really articulate, unconstrained forms language.
Without a forms language, REST web services are little more useful than RPC style web services. That's because the guy programming the service client has to understand, at design time, the semantics of each URL. Example: del.icio.us. You learn the algorithm for constructing URLs and write your program to build them given some parameters you collect from a user. It's the same idea as calling a remote procedure. Other "REST" services might just supply you with a menu of URLs, whether they honor GET or POST, and the media types you can send or receive. Again, you're doing it at design time.
RPC services force clients to understand them at design time. You have to read some documentation and construct your program so that it calls functions in some order that makes sense to that service.
REST services use "hypermedia as the engine of application state." One realization of that idiom is HTML forms. Forms are how the service bypasses the browser. The guy who wrote the browser does not understand what is in the form. But he knows it is an HTML form and he has the browser render it for you to complete. The form tells the browser how to serialize the fields you complete and POST them to the service. It is HTML forms that enable you to order a plane ticket, or a book, using the same piece of compiled software: the browser. The form is a little program the browser downloads and executes at run time. The result of executing the program is a string, or a multipart message, the browser can submit to the service to obtain some other resource representation -- which, like all the other HTML it traffics in, the browser does not "understand".
So how can a web service enable the same dynamic capability for machine, as opposed to human, agents? Here's the use case: You're dropping your own service into a brew of services running in some environment. And your service needs the results of other services as input to its own. It needs to locate those services in the brew. And it needs to invoke those services correctly and interpret the results. At design time, you don't understand how any of the other services work, or which services will be available; but you do understand the documents they traffic.
If you had a really intelligent automaton on the client side, it could retrieve a form document from any service telling it what parameters to retrieve and how to serialize them. But I'm pretty sure we're not going to have the intelligent automatons I outlined in a previous blue sky piece.
Instead, you have the capability to search. It's a lot like completing a form. It's more constrained than that, though. It's the kind of form that can only do one thing, for all applications.
So you're programming the travel reservations application. Your app can search a directory for the airline, auto rental, and hotel reservation services. It searches the airline service for flights from Austin to Atlanta leaving Monday, returning Wednesday. It searches for mid-size rental cars available in Atlanta. It searches for hotels in downtown Atlanta in a certain price range. Because we've standardized search, you program each of these interactions using the same model.
To complete the transaction, you would use the APP to create a purchase order document with the service.
It would be cool if services could annotate the search terms with RDF properties. OpenSearch doesn't try to get that sophisticated, and good for it. But to complete an airline reservation you're going to need to know how to search for "flight", and not have the search return some other object. You could draw the search terms from an airline ontology.
But if I suggest SPARQL as an alternative to OpenSearch, Bosworth and the free vs safe libertines will jump my shit. Maybe rightly so. I'm still re-educating.
Now OpenSearch promises that I can expose a search URL over my Atom service that can be used by search aggregators to do sort of intelligent searching.
If anybody can search my web service using a standard protocol, to discover URLs of resources they are interested in, it's the poor man's equivalent of having a forms language. Aren't 90% of the forms you fill out on the web some form of search?
I can force a lot of the semantics of my web service into search. What can't you model as a search? You can model UDDI as search. You can model any web catalog as a search. Heck, you can model solving a differential equation as a search.
Search may substitute for a really articulate, unconstrained forms language.
Without a forms language, REST web services are little more useful than RPC style web services. That's because the guy programming the service client has to understand, at design time, the semantics of each URL. Example: del.icio.us. You learn the algorithm for constructing URLs and write your program to build them given some parameters you collect from a user. It's the same idea as calling a remote procedure. Other "REST" services might just supply you with a menu of URLs, whether they honor GET or POST, and the media types you can send or receive. Again, you're doing it at design time.
RPC services force clients to understand them at design time. You have to read some documentation and construct your program so that it calls functions in some order that makes sense to that service.
REST services use "hypermedia as the engine of application state." One realization of that idiom is HTML forms. Forms are how the service bypasses the browser. The guy who wrote the browser does not understand what is in the form. But he knows it is an HTML form and he has the browser render it for you to complete. The form tells the browser how to serialize the fields you complete and POST them to the service. It is HTML forms that enable you to order a plane ticket, or a book, using the same piece of compiled software: the browser. The form is a little program the browser downloads and executes at run time. The result of executing the program is a string, or a multipart message, the browser can submit to the service to obtain some other resource representation -- which, like all the other HTML it traffics in, the browser does not "understand".
So how can a web service enable the same dynamic capability for machine, as opposed to human, agents? Here's the use case: You're dropping your own service into a brew of services running in some environment. And your service needs the results of other services as input to its own. It needs to locate those services in the brew. And it needs to invoke those services correctly and interpret the results. At design time, you don't understand how any of the other services work, or which services will be available; but you do understand the documents they traffic.
If you had a really intelligent automaton on the client side, it could retrieve a form document from any service telling it what parameters to retrieve and how to serialize them. But I'm pretty sure we're not going to have the intelligent automatons I outlined in a previous blue sky piece.
Instead, you have the capability to search. It's a lot like completing a form. It's more constrained than that, though. It's the kind of form that can only do one thing, for all applications.
So you're programming the travel reservations application. Your app can search a directory for the airline, auto rental, and hotel reservation services. It searches the airline service for flights from Austin to Atlanta leaving Monday, returning Wednesday. It searches for mid-size rental cars available in Atlanta. It searches for hotels in downtown Atlanta in a certain price range. Because we've standardized search, you program each of these interactions using the same model.
To complete the transaction, you would use the APP to create a purchase order document with the service.
It would be cool if services could annotate the search terms with RDF properties. OpenSearch doesn't try to get that sophisticated, and good for it. But to complete an airline reservation you're going to need to know how to search for "flight", and not have the search return some other object. You could draw the search terms from an airline ontology.
But if I suggest SPARQL as an alternative to OpenSearch, Bosworth and the free vs safe libertines will jump my shit. Maybe rightly so. I'm still re-educating.
Friday, September 23, 2005
Are data models passé?
In the free vs safe debate, free is winning. That's a debate not limited to programming languages. You see the same meme in the web services debates. Google does "free" for data. Adam Bosworth's pitching open, "dumb" search standards; so is Joe. Do we need formal logical data models?
We won't be able to impose them. No data architect will design a master schema or ontology over domains like, say, process control, or auctions. Instead, mediators like Google will infer models from content. Or each of us will contribute our bit to the global model by social bookmarking and tagging. The excitement in searches will be in augmenting the raw search results served up by the dumb search protocols, with the value a mediator like Google or del.icio.us adds in imposing their inferred models, making the searches faster or more accurate.
We won't be able to impose them. No data architect will design a master schema or ontology over domains like, say, process control, or auctions. Instead, mediators like Google will infer models from content. Or each of us will contribute our bit to the global model by social bookmarking and tagging. The excitement in searches will be in augmenting the raw search results served up by the dumb search protocols, with the value a mediator like Google or del.icio.us adds in imposing their inferred models, making the searches faster or more accurate.
Monday, August 29, 2005
World's most useful blog
It's sobering to realize how black is the information hole around New Orleans right now. Hurricane Katrina. Cell towers down and powerless. Land lines inoperative. We have isolated little spotlights from CNN and Fox News, but they sent their teams to some downtown hotels, same as any corporate traveler, so these reports have focused on downtown. It's a lot like reporting from Baghdad hotels about the invasion of Iraq. N.O. is huge and dense. So check out the Times-Picayune's blog for the real dope. They deserve a Pulitzer for getting the information out to those of us really needing it. They're assembling reports there from all over the city. I'm a New Orleans ex-patriate, and right now I'm awaiting here in Austin the arrival of some family refugees who made it out, and are headed to live with us for... who knows how long. The power's going to be off for a month, and you can't get a drink of water. On that blog, and nowhere else really, I've been able to get some glimmer of info about my relatives' and friends' neighborhoods.
Subscribe to:
Posts (Atom)